Run Apache Spark cluster on any public/private cloud using ElasticBox in few minutes
![]()
What is Apache Spark?
[As from Wikipedia] Apache Spark is an open-source data analytics cluster computing framework originally developed in the AMPLab at UC Berkeley. Spark fits into the Hadoop open-source community, building on top of the Hadoop Distributed File System (HDFS).
It is currently one of the most active and hot project in the Hadoop ecosystem, with wide speculation that it would eventually completely replace Hadoop. You can read more about it at:

About ElasticBox
[As from elasticbox.com] ElasticBox makes it as easy as possible to develop, deploy, and manage applications for any cloud infrastructure. Public, private, or hybrid cloud deployments across AWS, Google Compute, Azure, OpenStack, CloudStack, and VMware - all just need a few clicks.
ElasticBox enables you to write an application once, and deploy it on any cloud architecture without being locked on any one specific cloud. You can read more about it at:
Now assuming that you know about Apache Spark and the concepts in ElasticBox (which are just three: providers, boxes and instances), let us drill down on deploying Apache Spark via ElasticBox.
Note:
- Apache Spark "box"-es are not yet publically available. So, please drop me an email with your ElasticBox username, and I will share them with you.
- We are going to use AWS as a provider for this article
Part 1 takes you through the setup of a single node Apache Spark cluster (or the master node in case you proceed to Part 2), and
Part 2 takes you through a few extra steps to transform this single node Apache Spark into a production ready cluster
Part 1: Single node Apache Spark
First, let us create a single node Apache Spark, or if we want to deploy a multi-node Apache Spark cluster then this instance will act as the master nodeStep 1
Goto "Instances" tab in ElasticBox and click on "New Instance", then select "Shared with me" tab in the wizard, and then click on "Apache Spark Master"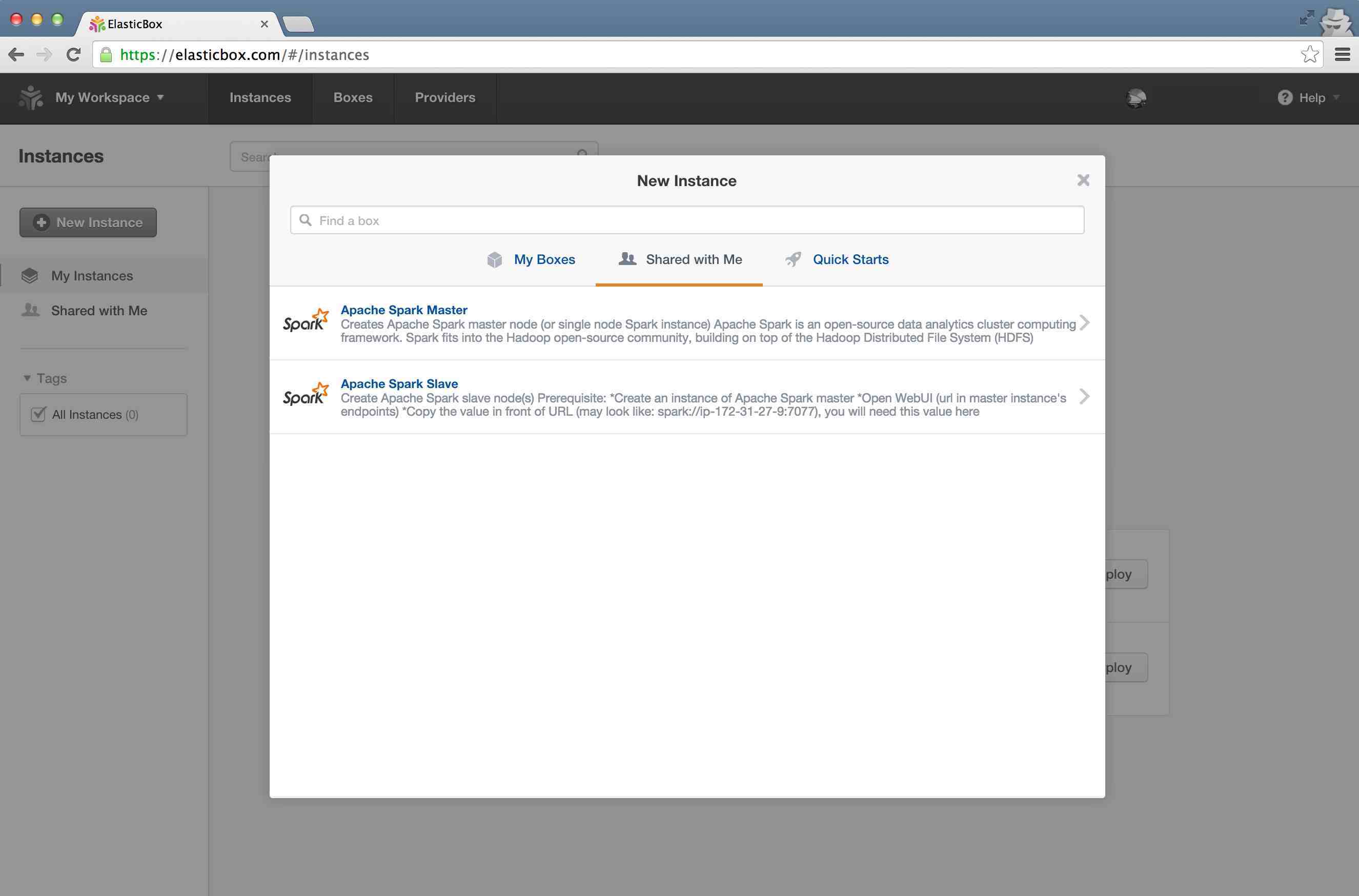
Step 2
In "Environment" option enter a name for this environment, and click on "New Profile" in the "Deployment Profile" option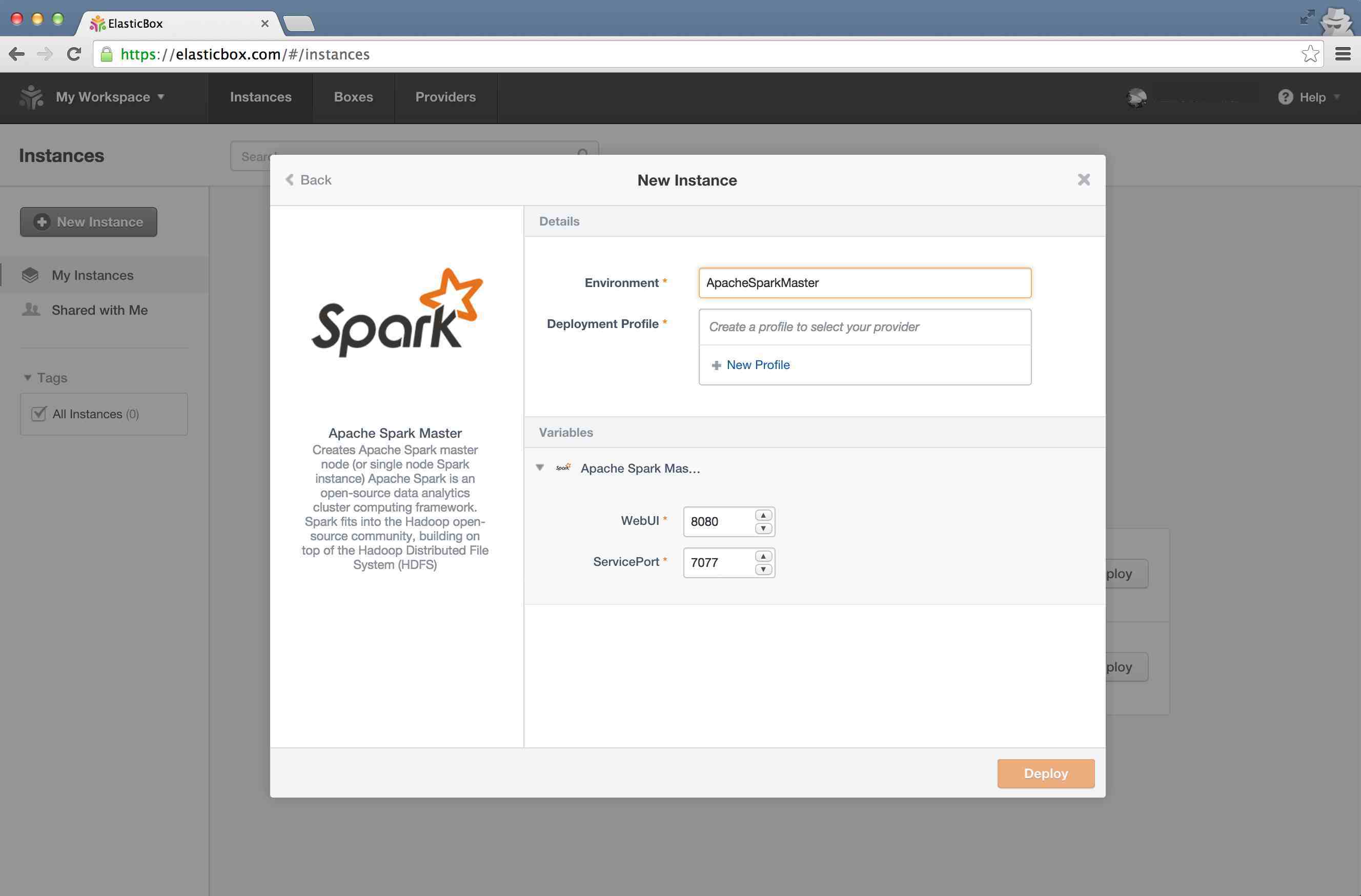
Step 3
Enter a "Name" for your profile, and click "Create"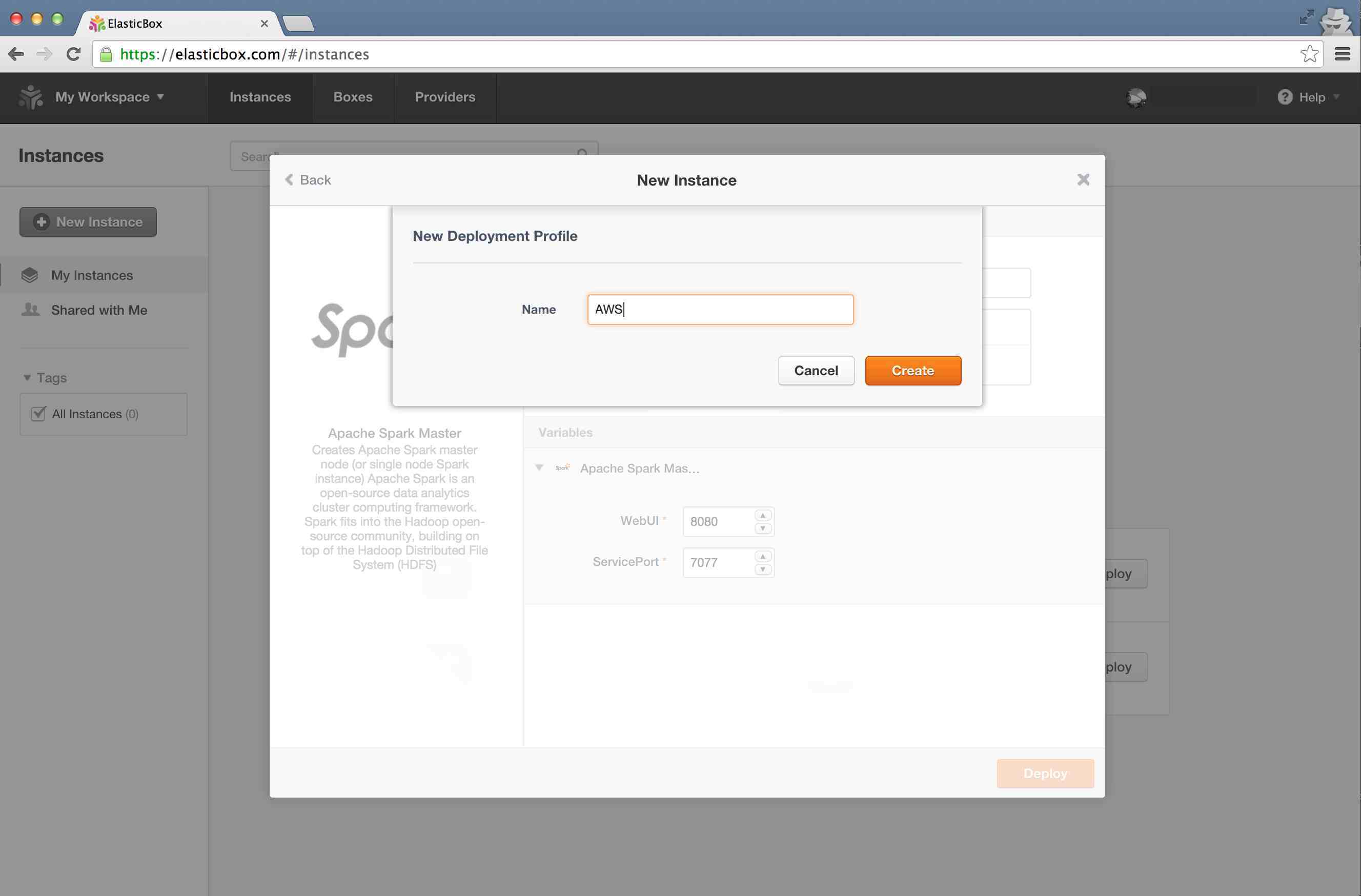
Step 4
While you can tweak other options, do tick the "Automatic Security Groups" option (this will make sure that the required ports for the service are opened by ElasticBox). Now click "Save"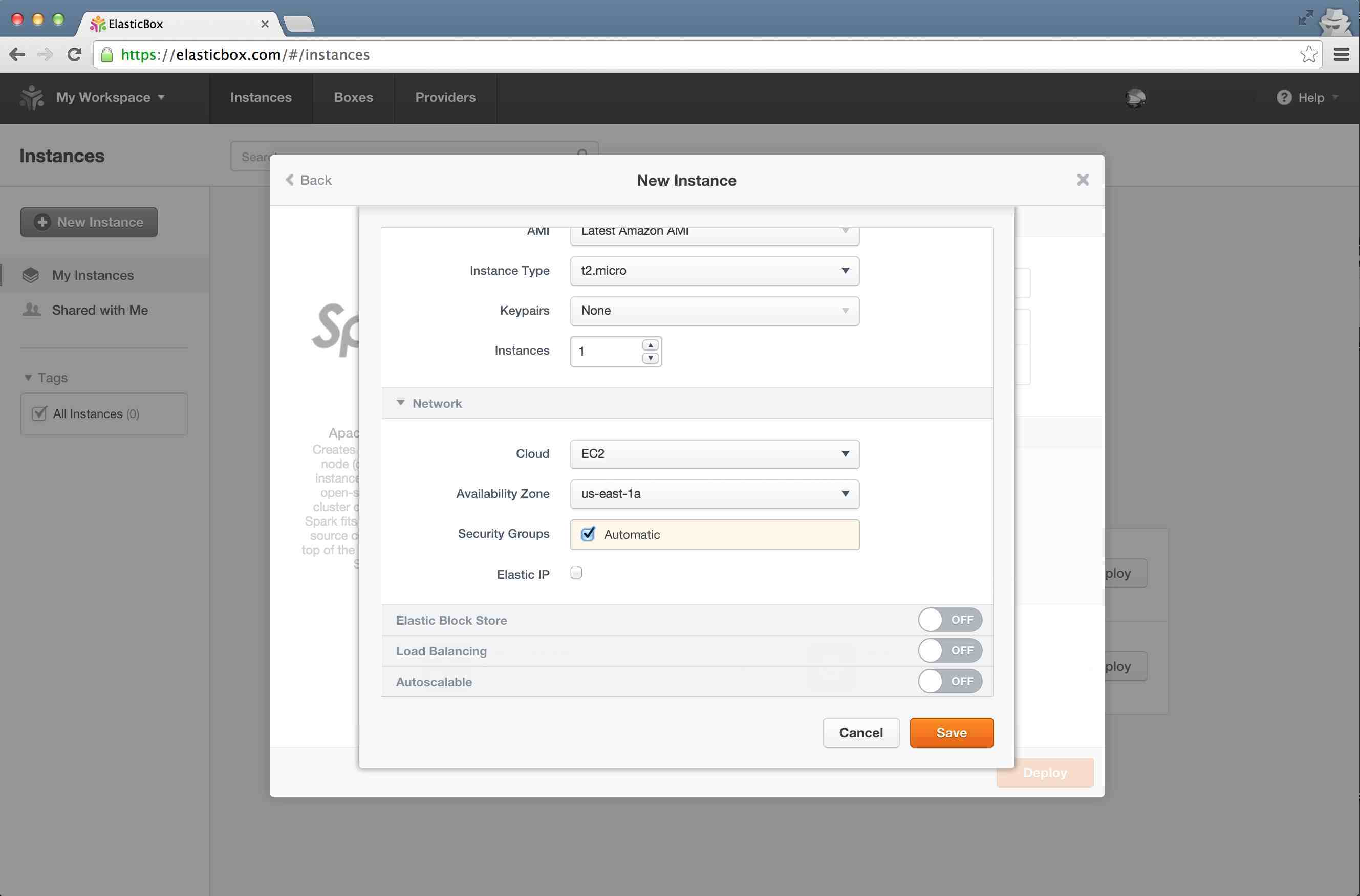
Step 5
You can change Web UI port and ther service port on this screen, but we are going to leave that intact for this tutorial. Now click on "Deploy"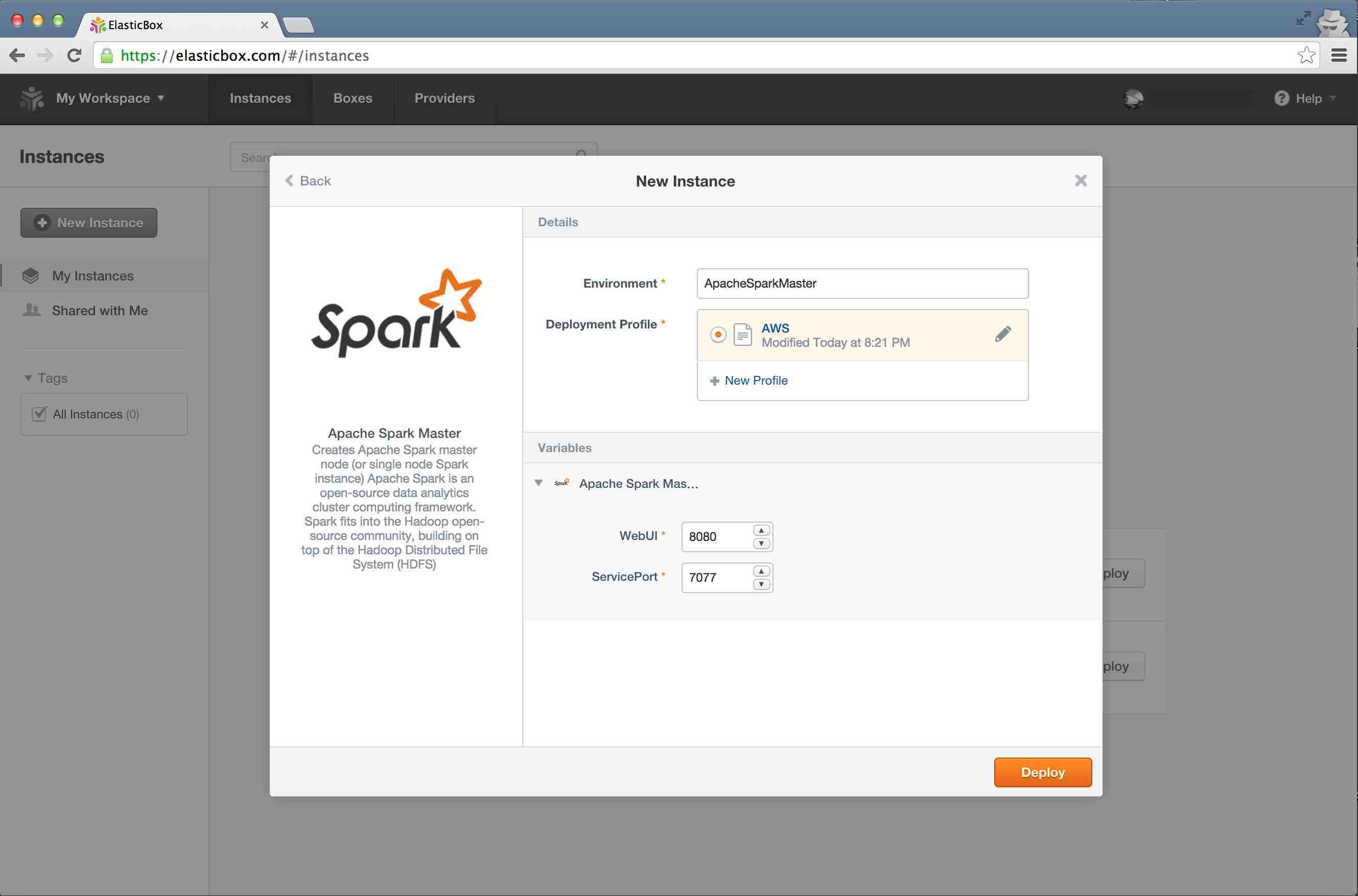
Step 6
You should now see the deployment in progress, as shown below. Once the status says as "Instance successfully deployed", click on "Endpoints" tab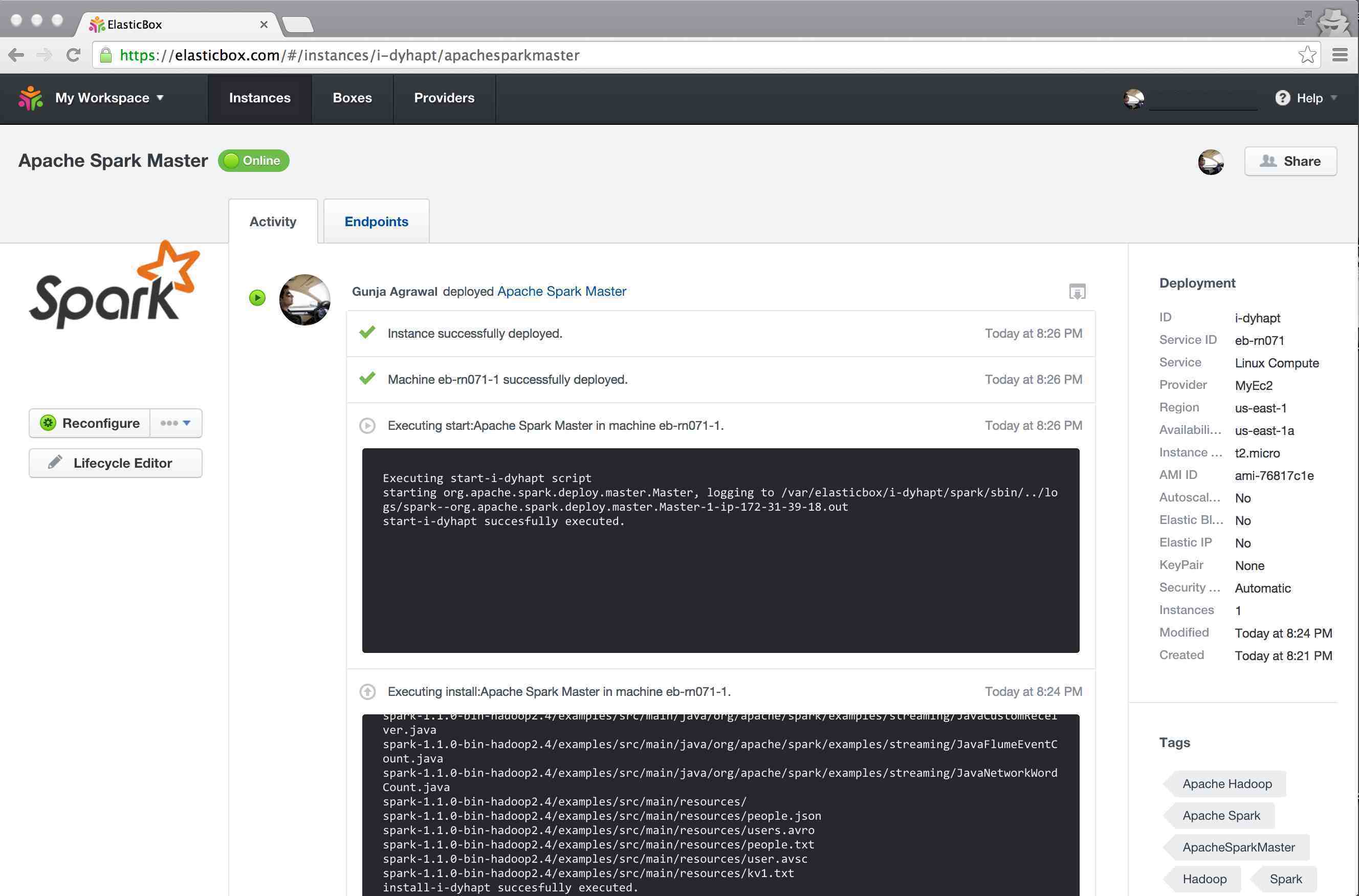
Step 7
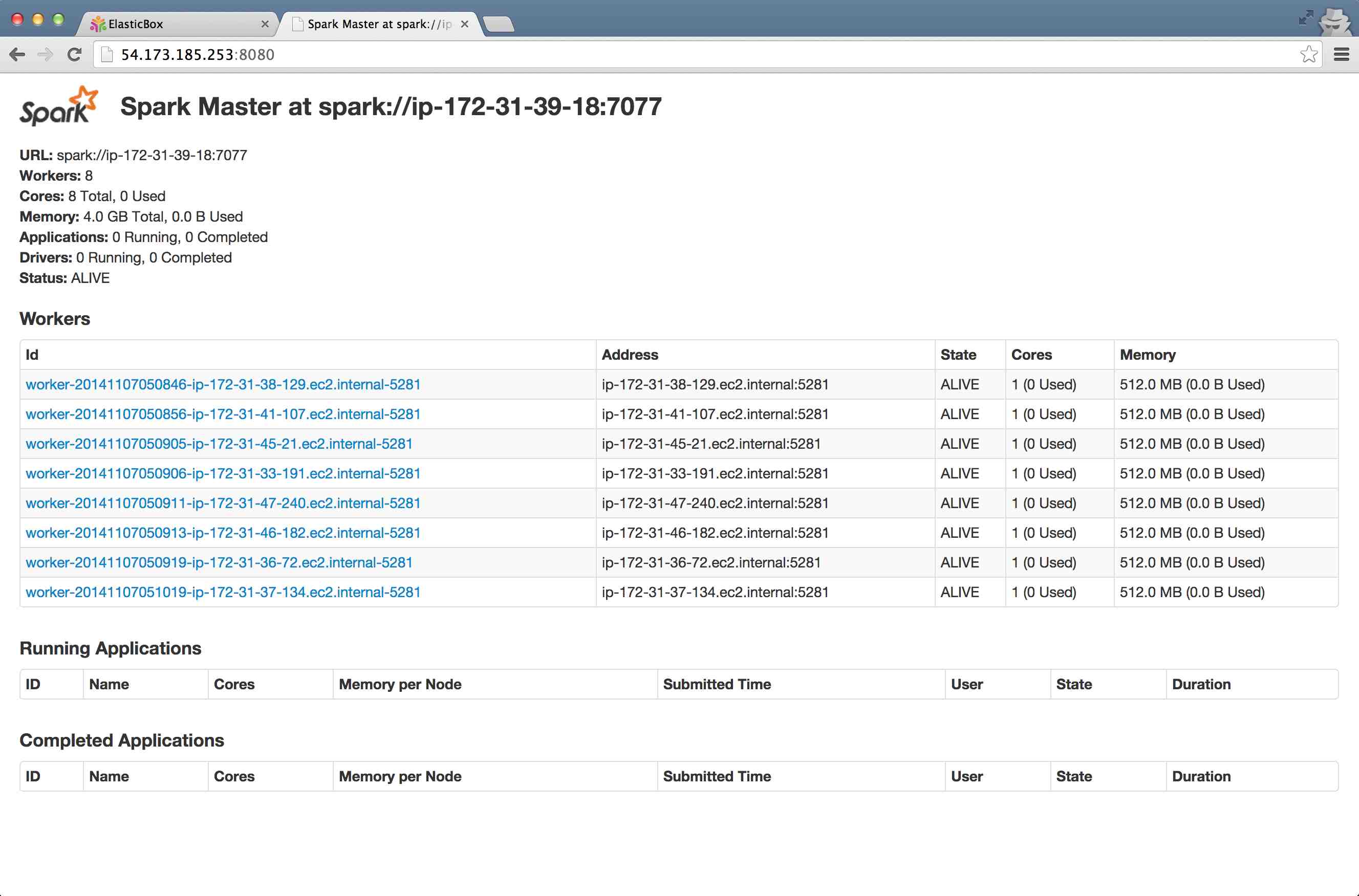
Copy the WebUI endpoint as listed here and open it in a new tab. That is your Apache Spark single node cluster running for you.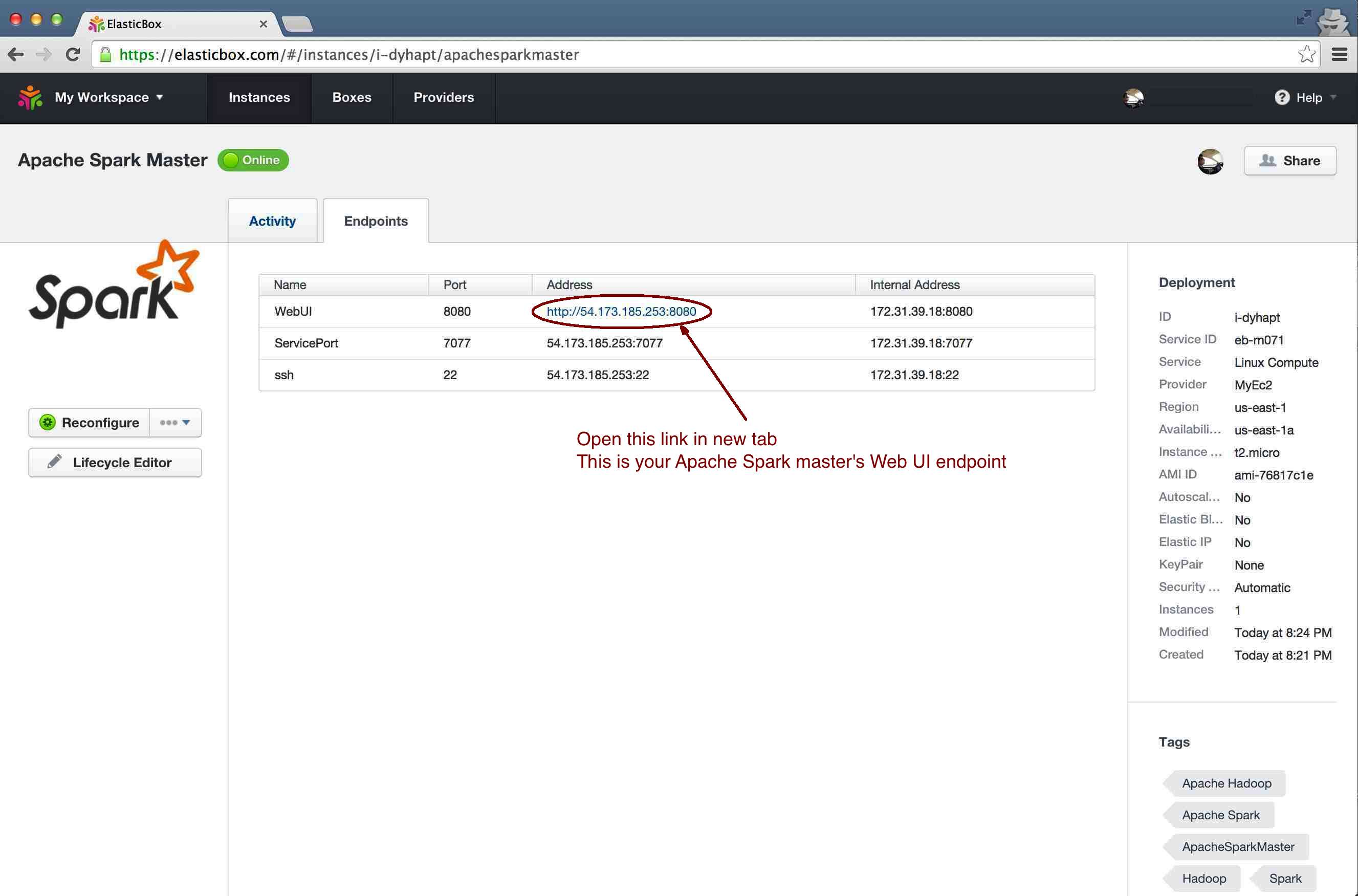
Step 8
IMPORTANT Copy the string listed in front of "URL", you will need it if you want to add more nodes (slaves) to the cluster (as described in part 2 of this tutorial). It should look something like: spark://ip-172-31-39-18:7077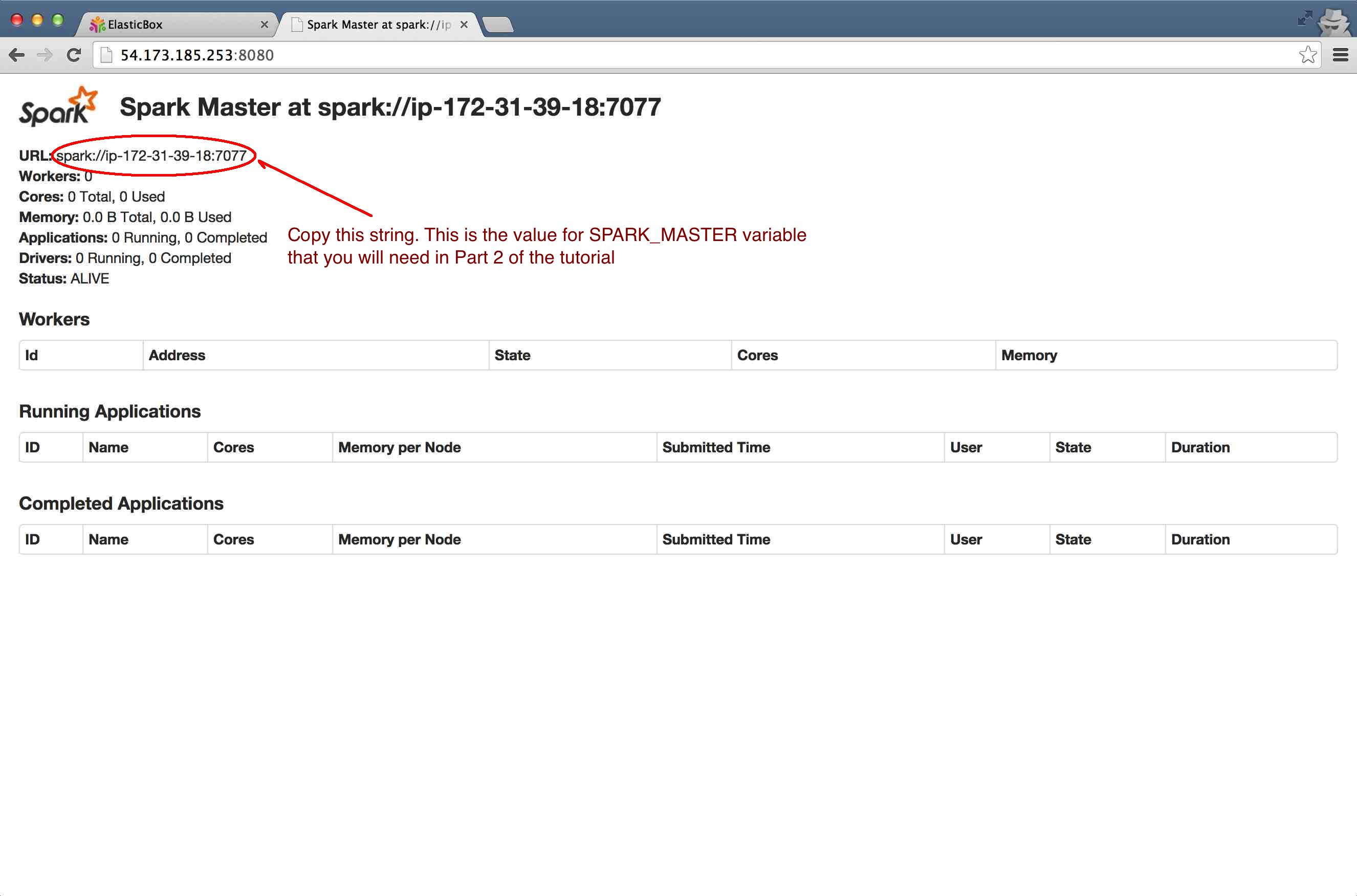
Part 2: Multi node Apache Spark
Congratulations, you have finished the hard part (was that really hard? :) ) Adding more nodes to the cluster is equally simple.Just repeat the same process, but with these little changes:
- In step 1, select "Apache Spark Slave" this time
- No change in step 2
- No change in step 3
- In step 4, change the value of "Intances" to the number of slaves / worker nodes that you want, and tick "Auto Scaling" option if you want more slave / workers to be added on the fly if any existing ones fail
- In step 5, you will be asked for SPARK_MASTER url, enter the string you copied from Apache Spark master's Web UI in Step 8 of Part 1. It should look something like: spark://ip-172-31-39-18:7077
- No change in step 6
- In step 7, you will see Web UI url for the slave(s) / worker(s)
- No change in step 7
- In step 8 let us re-open the Apache Spark master's Web UI. It should look something like below (the number of slaves you requested should have been added to the cluster)
A sneak peek at how our Apache Spark cluster looks like now: